Je copie un article analysant des données à propos d’un tournoi de starcraft pour illustrer d’autres possibilités.
APM moyen
tsv-summarize -H --mean AvgAPM --group-by Year IEM_games.tsv |
sed 's/\.[0-9]*//' |
tail -n+2 > data
gnuplot -p -e "set title 'APM Moyen par année';
set xlabel 'Années';
set ylabel 'APM';
set offsets 1,1,5,5;
plot 'data' w lp lw 2 ps 2 notitle, 'data' using 1:2:2 w labels offset -0.5,1 notitle"
Pour la suite il suffit de modifier la colonne concernée.
Les maps les plus jouées, plutôt facile sans tsv-utils :
cut -f7 IEM_games.tsv | sort | uniq -c | sort -nr | head
128 BlackpinkLE
96 CatalystLE
94 TritonLE
91 PortAleksanderLE
91 EphemeronLE
89 AbyssalReefLE
80 KairosJunctionLE
79 NightshadeLE
73 CyberForestLE
69 EternalEmpireLE
On enlève le -r du sort pour avoir les maps les moins jouées.
Cartes avec les temps moyens de jeu les plus longs. Là ça se complique pour les conversions.
J’utilise volontairement sed pour convertir en secondes puis awk pour convertir en mm:ss
pour montrer qu’il est possible d’utiliser les deux.
cut -f8 IEM_games.tsv | tail -n+2 |
sed -E 's/^([0-9]+):([0-9]+)/\1*60+\2/' |
bc -l |
sed '1 s/^/seconds\n/' |
paste IEM_games.tsv - |
tsv-summarize -H --mean seconds --group-by MapName |
sed 's/\.[0-9]*//' |
sort -t' ' -nrk2 |
awk -F'\t' '{printf $1" "(int($2/60))":";
printf "%02d\n", ($2%60)}' |
head | tsv-pretty
[ESL]Hardwire 16:27
[ESL]Gresvan 14:44
[ESL]Berlingrad 14:05
RomanticideLE 14:04
EternalEmpireLE 14:01
DuskTowers 14:01
JagannathaLE 13:57
2000AtmospheresLE 13:53
DeathauraLE 13:31
[ESL]GlitteringAshes 13:05
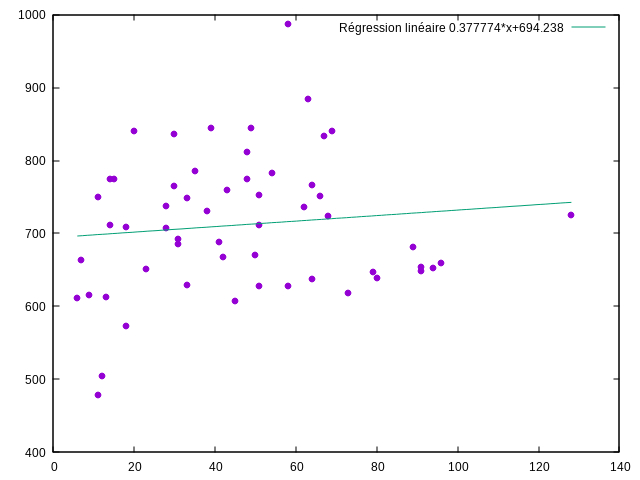
Correlation entre la fréquence de choix des cartes et la durée des parties ?
cut -f8 IEM_games.tsv | tail -n+2 |
sed -E 's/^([0-9]+):([0-9]+)/\1*60+\2/' |
bc -l |
sed '1 s/^/seconds\n/' |
paste IEM_games.tsv - |
tsv-summarize -H --mean seconds --group-by MapName |
sed 's/\.[0-9]*//' |
sort -t' ' -nrk2 |
head -n-1 |
sort > a
cut -f7 IEM_games.tsv | tail -n+2 |
tsv-summarize --count --g 1 |
sort > b
join -t' ' -j 1 a b > data
gnuplot -p -e "f(x) = a*x + b;
fit f(x) 'data' using 3:2 via a,b;
plot 'data' using 3:2 with points ps 1 pt 7 notitle,
f(x) ls 2 t sprintf('Régression linéaire %g*x+%g',a,b)"
Les box plot des certaines métriques selon le matchup :
cut -f11,14 IEM_games.tsv | tail -n+2 | sort > data
gnuplot -p -e "set style fill solid 0.50 border lt -1;
set pointsize 0.5;
set lt 51 lc 'dark-red'; set lt 52 lc 'midnight-blue';
set lt 53 lc 'dark-plum'; set lt 54 lc 'orchid4';
set lt 55 lc 'olive'; set lt 56 lc 'sea-green';
plot 'data' using (2):2:(0):1 with boxplot lt 51 lc variable notitle"
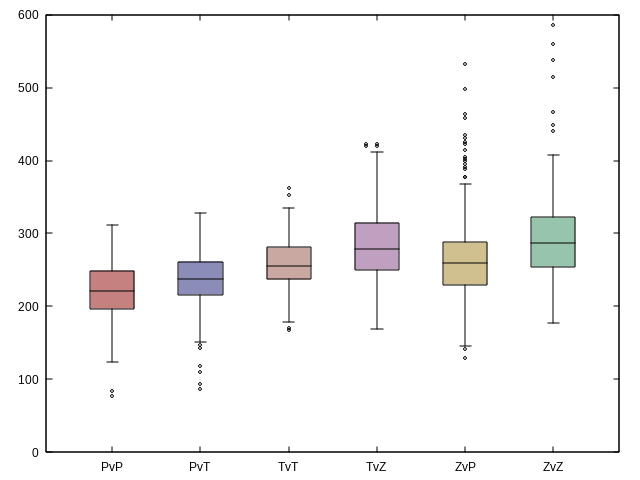
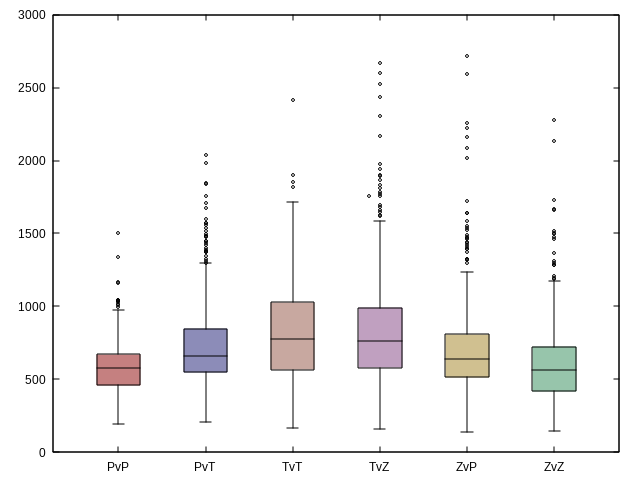
Même chose pour les autres variables en changeant le second champ du cut.
Pour la durée moyenne de match par matchup on reprend ce que l’on avait écrit précedemment, on retire le calcul de la moyenne et ce qui suit, on sélectionne le matchup et la durée en second, on tri, on affiche :
cut -f8 IEM_games.tsv | tail -n+2 |
sed -E 's/^([0-9]+):([0-9]+)/\1*60+\2/' |
bc -l |
sed '1 s/^/seconds\n/' |
paste IEM_games.tsv - |
cut -f11,26 |
sort |
gnuplot -p -e "set style fill solid 0.50 border lt -1;
set pointsize 0.5;
set lt 51 lc 'dark-red'; set lt 52 lc 'midnight-blue';
set lt 53 lc 'dark-plum'; set lt 54 lc 'orchid4';
set lt 55 lc 'olive'; set lt 56 lc 'sea-green';
plot '-' using (2):2:(0):1 with boxplot lt 51 lc variable notitle"
Les joueurs les plus jeunes
awk -F' ' '$4' IEM_players_info.tsv |
sort -t' ' -rk4 |
head |
cut -f1,4 > data
cut -f1 data |
xargs -I{} grep -m1 {} IEM_players.tsv |
cut -f5 |
paste data - > data2
cut -f2,3 data2 | tail -n+2 |
sed -E 's/([^\-]+).* ([0-9]*)/\2 - \1/' |
bc -l |
sed '1 s/^/Age\n/' |
paste data2 - |
cut -f1,3,4 | column -ts' '
Player Year Age
KRYSTIANER 2020 16
REYNOR 2019 17
CLEM 2019 17
GOBLIN 2019 17
WAYNE 2020 19
SKILLOUS 2019 18
VINDICTA 2020 20
OLIVEIRA 2021 21
COFFEE 2023 24
Les joueurs les plus âgés
awk -F' ' '$4' IEM_players_info.tsv |
sort -t' ' -k4 |
head |
cut -f1,4 > data
cut -f1 data |
xargs -I{} grep -m1 {} IEM_players.tsv |
cut -f5 |
paste data - > data2
cut -f2,3 data2 | tail -n+2 |
sed -E 's/([^\-]+).* ([0-9]*)/\2 - \1/' |
bc -l |
paste data2 - |
cut -f1,3,4 | column -ts' '
DIMAGA 2020 32
BRATOK 2019 30
NIGHTEND 2018 28
POLT 2016 29
KAS 2017 28
PIG 2016 27
BLY 2016 27
HUK 2016 28
KRR 2017 28
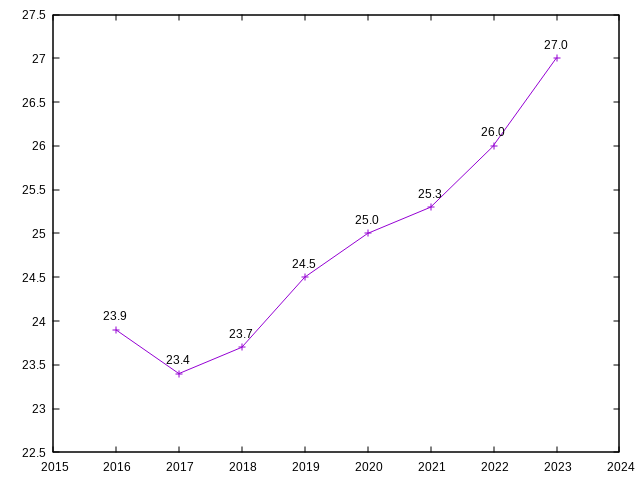
La moyenne des APM par année de compétition
cut -f2- IEM_players.tsv > data
tsv-join --filter-file IEM_players_info.tsv -k 1 -a 4 data |
cut -f4,14 |
cut -d'-' -f1 | tr ' ' '-' | tail -n+2 |
sed -E 's/^[0-9]+-$/print "no data\n"/' |
bc -l | sed '1 s/^/Age\n/' |
paste data - | cut -f4,14 | sed 's/no data//' |
tsv-summarize -H -x --mean 2 -g 1 | tail -n+2 |
sed -E 's/(\.[0-9])[0-9]*/\1/' > data2
gnuplot -p -e "set offset 1,1,0.5,0.5;plot 'data2' w lp notitle
, '' using 1:2:2 w labels offset 0,1 notitle"
Année de naissance moyenne par région
cut -f4,5 IEM_players_info.tsv | awk -F'\t' '$1' | awk -F'\t' '$2' |
sed -E 's/(-[0-9]{2}){2}//' |
sed -E 's/(US|MX|CA|BR)/America/;
s/KR/Korea/;
s/(AU|TW|CN|RU)/Asia/;
s/[A-Z]{2}$/Europe/' |
tsv-summarize -H --mean 1 -g 2 | tail -n+2 | sort > data
gnuplot -p -e "set style fill solid;
set yrange [1990:1998];
plot 'data' using 2:xtic(1) w histogram"
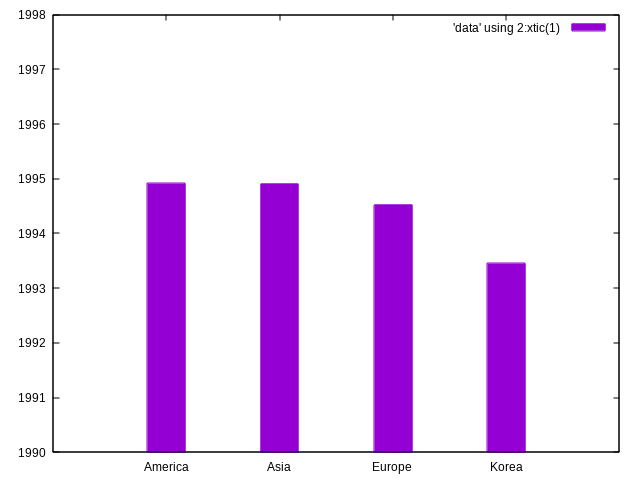
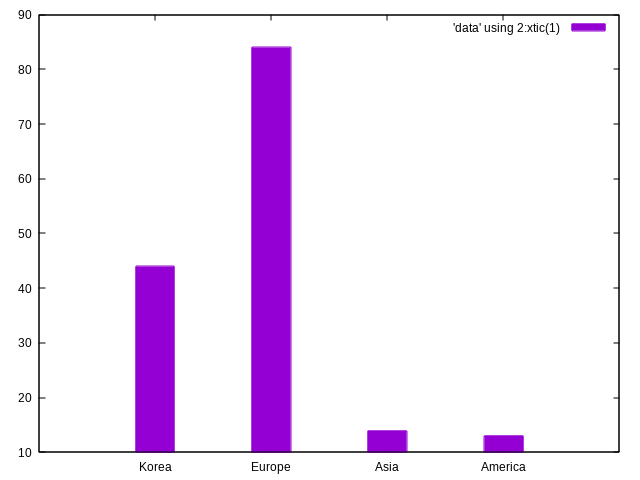
Nombre de joueur par région
cut -f5 IEM_players_info.tsv | awk -F'\t' '$1' |
sed -E 's/(-[0-9]{2}){2}//' |
sed -E 's/(US|MX|CA|BR)/America/;
s/KR/Korea/;
s/(AU|TW|CN|RU)/Asia/;
s/[A-Z]{2}$/Europe/' |
tsv-summarize -H --count -g 1 | tail -n+2 > data
gnuplot -p -e "set style fill solid;
plot 'data' using 2:xtic(1) w histogram"
Joueurs ayant joué le plus de secondes
cut -f7 IEM_players.tsv | tail -n+2 |
sed -E 's/^([0-9]+):([0-9]+)/\1*60+\2/' |
bc -l |
sed '1 s/^/seconds\n/' |
paste IEM_players.tsv - |
tsv-summarize -H --sum seconds -g Player |
sort -t' ' -nrk2
SERRAL 108508
SOLAR 106093
MARU 105444
DARK 105327
HEROMARINE 86769
...
Joueurs avec les parties les plus longues en moyenne
cut -f7 IEM_players.tsv | tail -n+2 |
sed -E 's/^([0-9]+):([0-9]+)/\1*60+\2/' |
bc -l |
sed '1 s/^/seconds\n/' |
paste IEM_players.tsv - |
tsv-summarize -H --mean seconds -g Player |
sort -t' ' -nrk2
PERCIVAL 1038.75
MATIZ 1014
VINDICTA 946.571428571
KEEN 897
MARINELORD 884.909090909
SPIRIT 874.178571429
CURE 871.394366197
...
APM moyen par joueur à travers toutes les compéitions. Bonne exemple de comment et pourquoi tsv-utils parfois c’est vraiment bien :
tsv-summarize -H --mean APM -g Player IEM_players.tsv |
sort -t' ' -nrk2
TLO 584.472222222
REYNOR 414.126213592
DRG 400.565217391
RAGNAROK 391.613636364
...
vs
cut -f2 IEM_players.tsv | tail -n+2 |
sort -u |
xargs -d'\n' -n1 sh -c 'printf "$1 ";
data=$(grep "$1" IEM_players.tsv);
echo "$(echo "$data" | cut -f9 | paste -s -d'+' | bc -l)\
/ $(echo "$data" | wc -l)" |
bc -l' -- |
sort -t' ' -nrk2
TLO 584.47222222222222222222
REYNOR 414.12621359223300970873
DRG 400.56521739130434782608
RAGNAROK 391.61363636363636363636
...
Les victoires
grep ' V ' IEM_players.tsv |
cut -f2 |
tsv-summarize --count -g1 |
sort -t' ' -nrk2
SERRAL 93
MARU 84
DARK 82
SOLAR 76
...
Corrélation APM victoires
grep ' V ' IEM_players.tsv |
cut -f2 |
tsv-summarize --count -g1 | sort > wins
tsv-summarize -H --mean APM --group-by Player IEM_players.tsv |
sed 's/\.[0-9]*//' |
tail -n+2 |
sort |
join -t' ' -j 1 wins - > data
gnuplot -p -e "f(x) = a*x**5 + b*x**4 + c*x**3 + d*x**2 + e*x + f;
fit f(x) 'data' using 2:3 via a,b,c,d,e,f;
plot 'data' using 2:3 with points ps 1 pt 7 notitle,
f(x) ls 2 t 'Regression'"
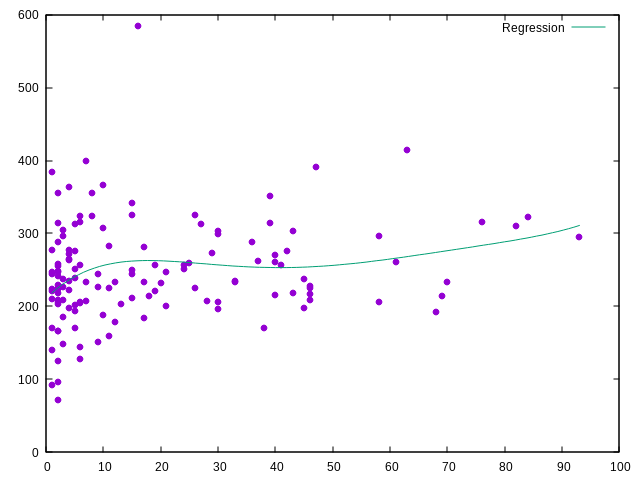
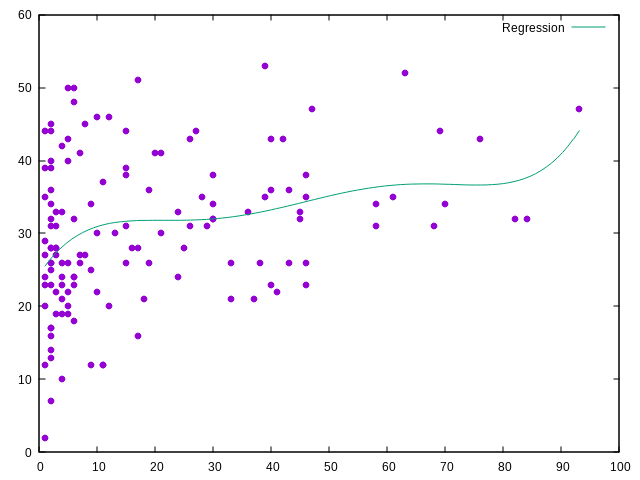
Pareil avec les SPM
tsv-summarize -H --mean SPM --group-by Player IEM_players.tsv |
sed 's/\.[0-9]*//' |
tail -n+2 |
sort |
join -t' ' -j 1 wins - > data
gnuplot -p -e "f(x) = a*x**5 + b*x**4 + c*x**3 + d*x**2 + e*x + f;
fit f(x) 'data' using 2:3 via a,b,c,d,e,f;
plot 'data' using 2:3 with points ps 1 pt 7 notitle,
f(x) ls 2 t 'Regression'"
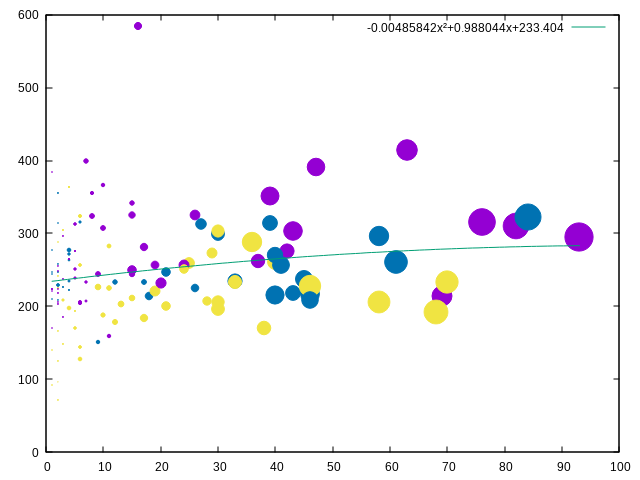
A nouveau la corrélation entre les APM et la quantité de victoire mais avec la taille des points étant vaguement proportionnelle à la quantité de map jouées et la couleur correspondant à la race du joueur1 :
grep ' V ' IEM_players.tsv |
cut -f2 |
tsv-summarize --count -g1 | sort > wins
tsv-summarize -H --mean APM --group-by Player IEM_players.tsv |
sed 's/\.[0-9]*//' |
tail -n+2 |
sort -k1 > apm
tsv-summarize -H --count -g Player IEM_players.tsv |
sort -k1 > nbgames
cut -f2,8 IEM_players.tsv |
sort -u | sort -t' ' -k1 > race
join -t' ' -j1 wins apm |
join -t' ' -j1 - nbgames |
join -t' ' -j1 - race 2>/dev/null |
sed 's/T$/6/;s/P$/5/;s/Z$/1/' > data
gnuplot -p -e "f(x) = a*x**2+b*x+c;
fit f(x) 'data' using 2:3 via a,b,c;
plot 'data' using 2:3:(\$4/30)::5 w points lc variable ps variable pt 7 notitle,
f(x) ls 2 t sprintf('%gx²+%gx+%g',a,b,c)"
Avec le même jeu de données on peut faire d’autres choses :
gnuplot -p -e "f(x) = a*x**2+b*x+c;
fit f(x) 'data' using 2:3 via a,b,c;
plot f(x) ls 2 t sprintf('%gx²+%gx+%g',a,b,c),
'data' using 2:3:1:5 w labels tc var font ',10'" 2> /dev/null
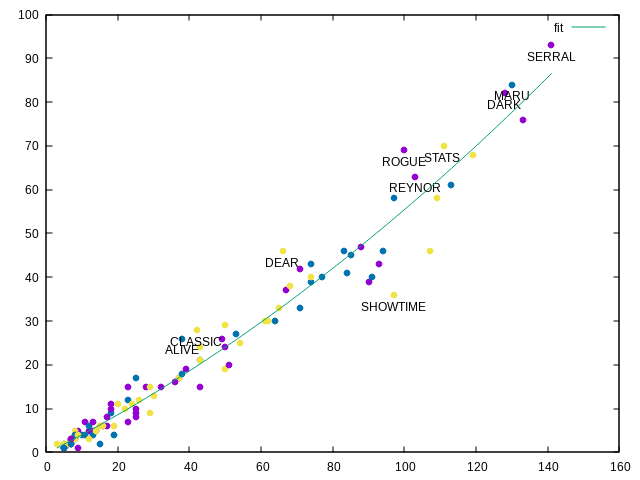
On peut aussi mettre des conditions sur le fait d’afficher certaines choses ou pas. Par exemple ici corrélation entre la quantité de parties jouées et le nombre de parties gagnées avec les noms affichés pour les personnes ayant joué plus de 25 maps et ayant un win rate meilleur que 60% ou un win rate inférieur à 0.4 :
gnuplot -p -e 'f(x)=x/2;
g(x)=a*x**2+b*x+c;
fit g(x) "data" using 4:2 via a,b,c;
plot "data" using 4:2:::5 w p lc variable ps 1 pt 7 notitle,
"" using 4:($2>25 && ($2/$4>0.6 || $2/$4<0.4) ? $2: NaN):1 w labels offset 0,-0.8 notitle,
g(x) ls 2 t "fit"' 2>/dev/null
%
-
dans le jeu… ↩