On m’a fait la remarque que mon activité sur le gitlab de l’université de Strasbourg n’était pas bien fournie :

N’utilisant plus beaucoup cette forge je me suis demandé à quoi cette frise ressemblerait pour les dépôts en local sur mon ordinateur. J’y ai vu un super exercice gnuplot.
L’énoncé
Admettons que l’on ait un jeu de donnée de la sorte :
nombre-commits date
0 1
0 2
0 3
1 4 2023 Oct 22
0 5 2023 Oct 23
0 6 2023 Oct 24
0 7 2023 Oct 25
En première colonne un entier, le nombre de commit, en seconde la date soit au format “numéro de la journée dans la semaine” ou “numéro de la journée dans la semaine, année, trois premières lettres du mois en anglais, numéro de la journée dans le mois”. Les deux colonnes sont séparées par une tabulation, les données dans la seconde colonne par un simple espace. La dernière ligne correspond à aujourd’hui, la première ayant une date complète à aujourd’hui - 1 ans, les quelques lignes avant le nombre de jours nécessaires pour remonter au dernier lundi de l’année précédentes. Ces lignes sont là pour compléter la première semaine de l’année.
Écrire un script gnuplot permettant de tracer un calendrier similaire à celui vu plus tôt.
Pourquoi ce format un peu étrange ?
Parce qu’il va faciliter l’écriture du script gnuplot mais pas au point de n’avoir besoin d’aucune astuce ou fonctionnalité un peu avancée. Lorsque l’on écrit du gnuplot on est fréquemment confronté au même dilemme : pour gérer de la complexité devrait-t-on ajouter du code en amont de gnuplot et lui préparer le meilleur des formats possible ou devrait-on alourdir le script gnuplot pour qu’il gère des sources de données moins spécifiques ? En fonction de votre objectif et de vos compétences en gnuplot la réponse peut varier.
Ici je souhaite aborder quelques éléments de gnuplot sans trop me perdre dans
des digressions ou des points très avancés. J’ai donc opté pour une source de
données arrangeante et un script gnuplot pas trop compliqué. A l’inverse si
j’avais voulu explorer toute la puissance de gnuplot et distribuer un script se
suffisant à lui même je l’aurais écrit pour pouvoir lire la sortie par défaut de
git log.
Le code final ainsi que le script permettant de générer ce tableau un peu étrange
sont disponibles ici : http://git.bebou.netlib.re/git-cal/log.html
Attention, je compte faire bouger ce dépôt qui risque de fortement dévier
du code décrit dans cet article. Pas de panique si les deux divergent. Je fige
le code de l’article tel qu’il est avec ses défauts, c’est d’abord un outil
pédagogique.
Addendum : après une lecture commune de l’article avec des collègues
je me suis rendu compte que le calcul des ordonnées des jours était
inutilement complexe. Initialement j’ai eu l’idée d’ajouter les “faux”
jours en début de fichier. Pour pouvoir savoir combien en ajouter j’ai inscrit
le numéro de la journée dans la date et se faisant l’ordonnée que l’on cherche
justement à calculer. La donnée se trouvant déjà dans le fichier et n’ayant pas
besoin d’être calculée depuis le numéro de la ligne la formule pour calculer y
pourrait être :
word(strcol(2),1) au lieu de
int($0*-1)%7
On pourrait penser que cela simplifierait le script de génération du TSV mais le
numéro de la ligne est également utilisé pour calculer le numéro de la semaine
pour les x ! Pour se débarrasser totalement des petites formules mathématiques
malines il faudrait également insérer le numéro de la semaine dans le fichier .
Cependant cela ferait moins d’occasions d’apprendre des trucs dans cet article.
Conclusion : Pour des raisons pédagogiques je laisse l’article tel qu’il
est même si c’est un peu alambiqué mais je modifie le code dans le dépôt
git-cal pour le simplifier. Ne soyez pas étonné·es s’ils ne correspondent pas.
Au contraire cela peut être un bon exercice pour voir ce qui a changé depuis.
Une référence pour s’aider
Je dois une grande partie de ce que je sais au livre “Gnuplot in Action, Second Edition” de Philipp K. Janert, ISBN 9781633430181. Je l’ai si vous voulez. Le bouquin couvre jusqu’à la version 5.5 de gnuplot et n’intègre donc pas les nouveaux trucs cools de la récente version 6 mais pas grave. On peut déjà faire bien assez avec l’existant.
Si vous voulez tenter de résoudre l’exercice vous même il y a tout ce dont vous avez besoin dans ce livre y compris une solution presque toute faite dans l’annexe D.
De 0 à 100 en 11 étapes
Pour info, voici le résultat final :

script pour graph
Étape 1
Conseil trivial : lorsque l’on se lance dans la création d’un graphique avec gnuplot1 je suggère de toujours commencer par le graph le plus simple. Cela permet de rapidement :
- de confirmer que l’environnement de dev et le code de base sont bons
- de confirmer que les données sont les bonnes
- d’avoir un début d’intuition de ce qu’il y a dans le jeu de données
Ça tombe bien, c’est l’une des forces de gnuplot. Avec la ligne :
plot 'nbofcommits.tsv' using 0:1 with points
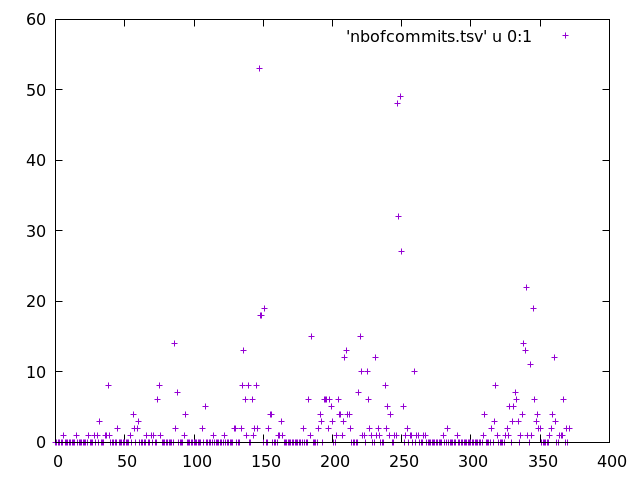
script pour graph
On obtient instantanément un nuage de point. En abscisse le nombre de jours depuis un an, en ordonnée le nombre de commits. On confirme visuellement que tout semble être correct : on a une majorité de journées à zéro commits, le reste entre 1 et 50, un gros trou durant l’été. Mais nous sommes encore bien loin de l’arrivée.
La commande plot, le cœur véritable de gnuplot, se découpe ainsi :
plot: le nom de la commandenbofcommits.tsv: le chemin du fichier à tracerusing: un “modificateur” permettant de préciser quelle colonne de données tracer0:1: les identifiant des colonnes à utiliser au formatx:ywith: un autre modificateur permettant d’indiquer avec quel “style” tracer les donnéespoints: le style en question
Si l’on met tout ça bout à bout en français, on a demandé à gnuplot :
Affiche la première colonne du fichier
nbofcommits.tsven fonction du numéro de ligne en traçant des points.
Pour les identifiants de colonnes 1 désigne la première colonne, 2 la
seconde. Pour tracer la seconde en fonction de la première il faut écrire 2:1.
La colonne 0 est spéciale, c’est une pseudo-colonne qui contient pour chaque
point le numéro de la ligne en cours. Je reviens dessus plus
tard. Ainsi 0:1 trace les valeurs contenues dans la
colonne 1 en fonction du numéro de ligne auxquels elles apparaissent.
Avec le fichier
2
4
8
16
32
La commande
plot 'nbofcommits.tsv' using 0:1 with points
trace la fonction puissance de 2. A savoir, vous risquez de rencontrer des commandes du type :
plot 'nbofcommits.tsv' using 1 with points
# ou
plot 'nbofcommits.tsv' using :1 with points
Pas de panique, cela fonctionne parce que si la colonne x n’est pas précisée
alors c’est la pseudo-colonne 0 qui est utilisée. Ces deux commandes sont donc
équivalentes à ce que l’on a écrit dans notre script.
Étape 2
Super sauf que l’on veut des carrés ! Rien de plus simple, on peut ajouter suite
au modificateur with le type de point à utiliser. Il se trouve que le numéro 5
est un carré rempli. Vous pouvez consulter les points à votre disposition en
lançant la commande test. Chez moi voilà ce que cela donne :
On le précise
plot 'nbofcommits.tsv' using 0:1 with points pointtype 5
et hop:
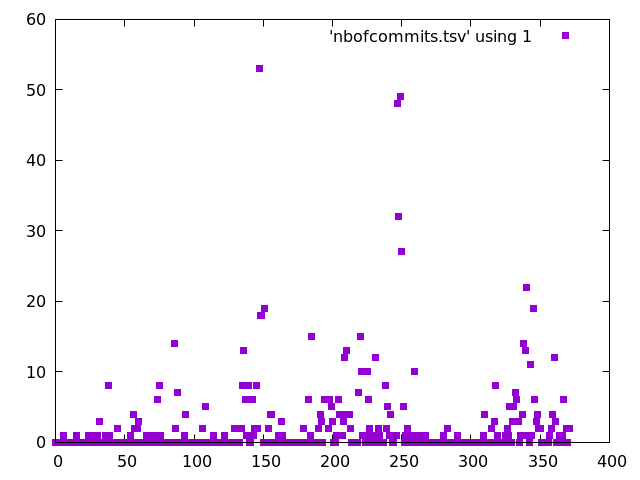
script pour graph
Étape 3
À ce stade la graphique reste linéaire dans le temps et encode la quantité de commits par les ordonnées et non pas par la couleur. Remédions d’abord à cette histoire d’ordonnées. Notre souhait est que l’ordonnée d’un carré corresponde à son emplacement dans la semaine. Les lundi en haut de chaque colonne, les dimanche en bas et rebelotte pour la prochaine semaine. Heureusement2 notre fichier commence un lundi et ne saute aucune journée3. On a donc le pattern suivant :
ligne 1 -> lundi
ligne 2 -> mardi
[...]
ligne 7 -> dimanche
ligne 8 -> lundi
Un peu d’expérience avec les maths et/ou la programmation permet de déceler qu’il est possible de jouer avec le modulo des numéros de ligne. En effet :
0%7 = 0, lundi -> 0
1%7 = 1, mardi -> 1
[...]
6%7 = 7, dimanche -> 7
7%7 = 0, lundi -> 0
Pourquoi on commence par 0 plutôt que 1 ? Parce qu’en informatique on commence
souvent par zéro et que c’est le cas de gnuplot quand on lui demande le numéro
d’une ligne. Ainsi, si l’on pouvait donner en y à la commande plot non pas
la valeur dans la première colonne mais le modulo de la ligne en cours on
pourrait jouer sur la hauteur des carrés comme on le souhaite. C’est ce que
permettent la fonction column et l’opérateur % :
plot 'nbofcommits.tsv' using (int(column(0))%7) with points pointtype 5
column permet d’accéder, en plus des colonnes du fichier, à ce que gnuplot
appelle des “pseudo-colonnes” ou “pseudocolumns” en anglais. Ces colonnes
n’existent pas dans le fichier et sont tenues à jour par gnuplot pour des
raisons pratiques. Dans la pseudo-colonne numéro 0 on retrouve le numéro de la
ligne courante. Ainsi pas besoin de l’ajouter à notre jeu de donnée ! On
convertit ce que nous renvoie la fonction en entier avec int()4 pour
pouvoir calculer le modulo 7. On notera que la totalité de l’opération est entre
parenthèse là où auparavant on indexait les colonnes directement avec des
entiers. Ces parenthèses permettent d’introduire une “inline transformation” ou
transformation en ligne. L’expression entre les parenthèses sera évaluée pour
chaque ligne et son résultat utilisé pour la colonne correspondante. En gros, si
vous voulez faire des maths ou appeler des fonctions à un endroit où vous auriez
normalement du inscrire une valeur particulière, utilisez des parenthèses.
On constate qu’effectivement tous les carrés se sont rangés en sept lignes, de 0 à 6 :
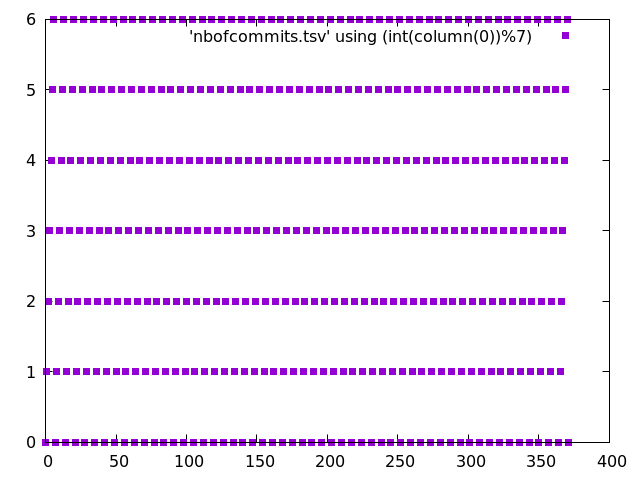
script pour graph
Étape 4
On pourrait penser que les carrés se sont également alignés en colonne mais c’est une illusion. Chaque carré est un peu plus à droite que le précédent. Pour s’en convaincre on peut élargir le graphique qui avait pour l’instant les dimensions par défaut de gnuplot. J’opte pour une largeur conséquente de 2000 pixels et une hauteur correspondant au ratio du nombre de semaines sur le nombre de jours par semaine. Cela devrait nous donner un graphique final plutôt équilibré :
width=2000
set term pngcairo size width,(width/(52/7))
La première ligne correspond à la création d’une variable. La seconde détermine
le terminal que gnuplot ciblera. Sans rentrer dans les détails, gnuplot sait
tracer pour plusieurs “terminaux” différents. Historiquement ces “terminaux”
pouvaient être de vrais terminaux physiques. Aujourd’hui cela est plutôt synonyme
de types ou de formats de sortie (png, jpeg, latex, svg etc). C’est en
choisissant le terminal que l’on peut également modifier la taille de la sortie.
J’utilise ici pngcairo qui fait de jolis png mais png est également dispo
quoi que un peu plus vieillot pour un rendu peut-être un peu moins joli. Le
terminal pngcairo peut avoir tendance à générer des fichiers un peu gros mais
la marge de progression étant grande, l’utilisation d’outils type
optipng est recommandée.
A noter le retour des parenthèses pour faire un rapide calcul là où nous aurions normalement du fournir un entier.

script pour graph
On remarque mieux le décalage horizontal des carrés. On va y remédier.
Étape 5
Comme on l’a fait pour les ordonnées, il convient de trouver le pattern adéquat pour les abscisses. On souhaite que les paquets de 7 lignes dans le fichiers soient tous sur la même colonne :
ligne 0 -> lundi semaine 1, 0/7 -> 0
ligne 1 -> mardi semaine 1, 1/7 -> 0,nnn
[...]
ligne 6 -> dimanche semaine 1, 6/7 -> 0,nnn
ligne 7 -> lundi semaine 2, 7/7 -> 1,nnn
ligne 8 -> mardi semaine 2, 8/7 -> 1,nnn
On remarque que la partie entière de la division du numéro de ligne par 7
devrait correspondre à notre besoin. En plus le fait que les numéros de lignes
commencent à 0 nous arrange ! Chouette ! La fonction floor va nous permettre
de répondre à notre besoin :
x(nl) = floor(nl/7)
y(nl) = int(nl)%7
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5
On découvre ici que l’on peut créer nos propres fonctions. gnuplot permet
d’écrire des fonctions qui peuvent ensuite être appelées dans différents
contextes comme ici dans une transformation en ligne. Deuxième nouveauté
l’utilisation du raccourci $0. Il est équivalent à column(0). De manière
générale quand vous voulez, à l’intérieur d’une transformation en ligne,
accéder à une valeur numérique contenue dans la Nième colonne alors vous
pouvez écrire column(N) ou $N.
Ainsi :
(int(column(0)/7) est devenu
(int($0)/7) que l'on met dans une fonction pour écrire
(x($0))

script pour graph
Super, nos carrés sont tous bien alignés !
Étape 6
C’est super mais on voit pas grand chose. Puis les axes ne nous servent pas vraiment. Puis la légende nous plus. Faisons une petite pause pour nettoyer tout ça. Premièrement retirons les axes avec, au choix :
set border 0
unset border
Les arguments de set border paraitront étranges sauf aux personnes manipulant
le chmod depuis leur plus tendre enfance. En effet, il sont encodés sur quatre
bits, chacun déterminant si l’un des bords est tracé ou pas. Le bit de poids le
plus faible encode l’affichage de l’axe du bas, le second celui de gauche, le
troisième celui du haut et la quatrième celui de droite. Ainsi 0110 veut dire
“afficher l’axe de gauche et celui du haut”. L’argument est la représentation
décimal de la valeur, ici 8*0+1*4+1*2+1*0=6. Il est également possible de
l’écrire set border 2+4. Dans notre cas rien de tout ça ne nous importe
puisque l’on ne veut rien. Par ailleurs unset border et set border 0 sont
équivalents.
Deuxièmement, retirons la légende :
unset key
Troisièmement retirons les “tics” :
unset tics
Finalement agrandissons les points en ajoutant un style après with :
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5 pointsize 4
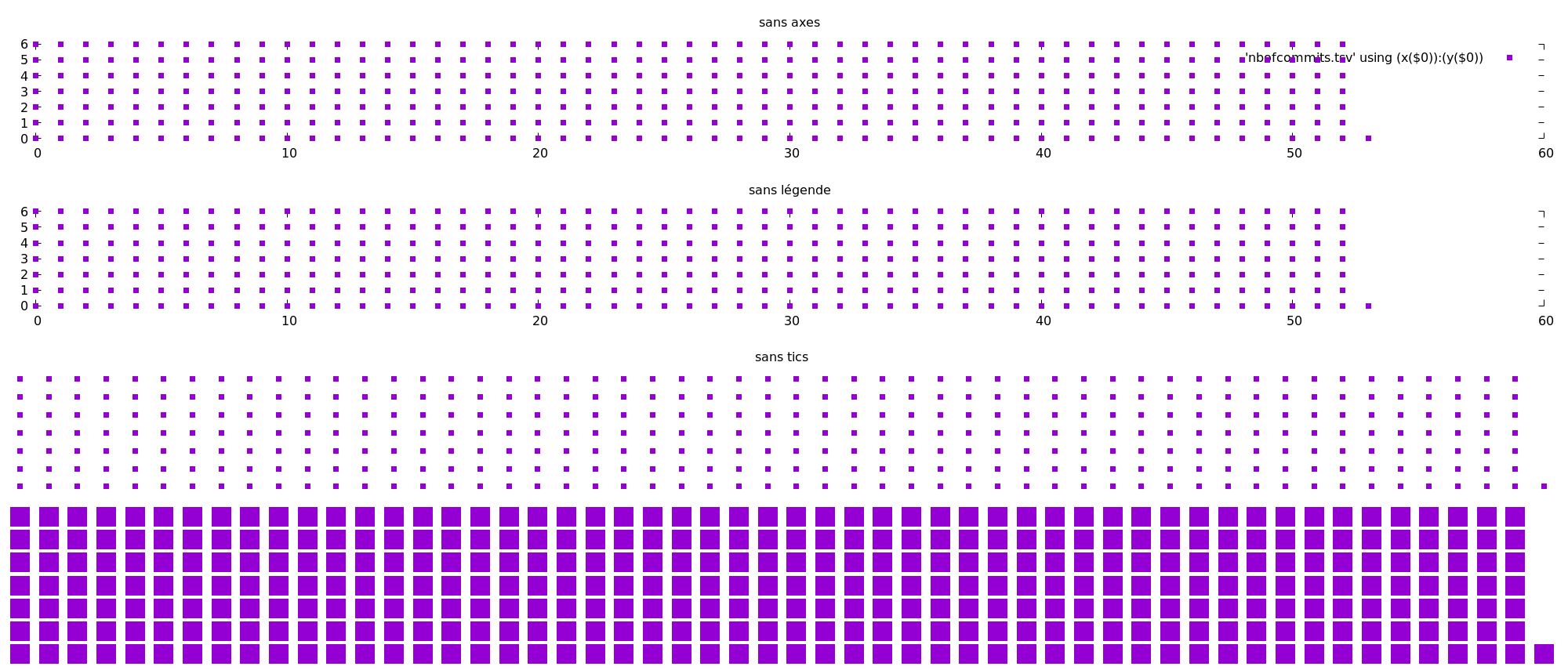
script pour graph
Le graph ci-dessus est un collage des étapes successives. Il est possible de
réaliser des graphiques comme celui-ci avec la commande set multiplot.
Chaque appel successif de la commande plot ajoutera un graphique supplémentaire
à la figure. La plupart du temps cela est utile pour tracer plusieurs graphs les
un à côté des autres comme ici. Pour que cela soit pratique multiplot peut
prendre un argument layout qui prendra en argument deux entiers,
respectivement le nombre de lignes et le nombre de colonnes à remplir. Ainsi le
graph ci-dessus a été construit comme ceci de façon à voir les effets des
commandes :
set term pngcairo size width,(width/(52/7)*3)
set multiplot layout 4,1
set border 0
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5
unset key
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5
unset tics
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5
plot 'nbofcommits.tsv' using (x($0)):(y($0)) with points pointtype 5 pointsize 4
Plus rarement multiplot permet, sans utilisation de layout, de tracer
n’importe où pour, par exemple, insérer un petit graph dans un autre et créer un
effet de “zoom”.
Étape 7
A un moment où à un autre il va falloir s’occuper de la couleur. Il y a au moins deux façons de faire varier la couleur de ce que l’on trace en fonction des données dans gnuplot.
La première est d’utiliser une colonne de couleur dédiée dont on ira chercher les valeurs dans le fichier. L’aide de gnuplot dit :
When using the keywords
pointtype,pointsize, orlinecolorin a plot command, the additional keywordvariablemay be given instead of a number. In this case the corresponding properties of each point are assigned by additional columns of input data. Variable pointsize is always taken from the first additional column provided in ausingspec. Variable color is always taken from the last additional column.
Autrement dit, en plus des colonnes x et y que l’on a jusque là utilisé il en existe d’autres qui sont utilisées pour faire varier d’autres caractéristiques des points. Ainsi
plot 'nbofcommits.tsv' using (x($0)):(y($0)):1 with points pointtype 5 pointsize 4 linecolor variable
Dit à gnuplot d’aller chercher la couleur du point dans la première colonne. Or,
l’une des manières que gnuplot a d’identifier les couleurs est par des entiers
de 0 à 155 faisant référence aux couleurs prédéfinies par défaut de gnuplot.
C’est d’ici que vient le superbe violet, c’est la couleur 1. Vous pouvez voir
toutes les couleurs dans l’image test de l’étape 2.

script pour graph
Les couleurs que l’on obtient ne veulent pas dire grand chose puisque l’on indexe les 15 couleurs par défaut avec le nombre de commits durant cette journée. Ce qu’il va nous falloir c’est un gradient de couleur qui représente une intensité.
Étape 8
gnuplot propose une fonction de palette de couleur. Elle peut être déclarée de plusieurs manières mais nous allons voir la suivante :
set palette defined ( 0 "#EEEEEE", 1 "light-blue", 20 "blue", 50 "dark-blue" )
Comme vu précédement les couleurs peuvent être identifiées de plusieurs
manières différentes. En plus d’un entier faisant référence à l’une des 16
couleurs prédéfinies, quelques couleurs sont nommées et l’utilisation des codes
hexadécimaux est également possible. Chaque couleur nommée possède trois
valeur, celle par défaut, une plus claire nommée light- et une plus sombre
nommée dark-. Ainsi au dessus on décide d’attribuer à la valeur 0, c’est à
dire aux journées sans commits, un gris très clair, à la valeur 1 le bleu
clair, la valeur 20 le bleu et la valeur 50 le bleu foncé. gnuplot est
suffisamment intelligent pour créer une palette continue entre les valeurs.
Ainsi 35 aura pour couleur celle à mi chemin entre blue et dark-blue. Bien
sûr j’ai choisi les valeurs de façon à ce que le graph soit intéressant
visuellement pour mon activité mais on peut les adapter. Un moyen de le rendre
dynamique serait d’utiliser la commande stats pour récupérer le minimum, le
maximum, la moyenne etc et, sur cette base, construire une palette appropriée.
Cela sort du périmètre de cet exercice donc je passe.
Afin de mettre à profit notre palette il suffit de remplacer le mot clef
variable utilisé précedemment par palette :
plot 'nbofcommits.tsv' using (x($0)):(y($0)):1 with points pointtype 5 pointsize 4 linecolor palette

script pour graph
Trois remarques :
- On ne respecte plus exactement l’exercice puisque dans le graph gitlab il n’existe que quatre couleurs prédéfinies pour des intervalles de valeurs. Je trouve que ce système de palette est plus cool donc je me permets de dévier.
- Notre commande
plotcommence à être très longue, on verra comment réduire sa taille bientôt. - On peut pas enlever le gros rectangle à droite qui faute de ne pas avoir de légende n’est pas bien utile ?
Étape 9
Ce rectangle automatiquement ajouté lorsque l’on utilise une palette est appelé
colorbox. Il est très utile pour la légende dans la majorité des cas mais pas
ici. Pour le retirer on suit la même logique que pour les autres décorations :
unset colorbox
Maintenant que l’on a une vision du nombre de commits par jour on se rend compte
d’une petite bêtise faite plus haut et difficile à déceler. Le tout premier
“vrai” jour de notre jeu de donnée est un dimanche, avec un commit puis plus
rien pour un moment, le tout dernier un lundi. On repère le dimanche en question
tout en haut à gauche, le lundi tout en bas à droite. Or on veut que les
colonnes commencent un lundi et terminent un dimanche. Pour y arriver il faut se
souvenir que tout cela est tracé dans un repère. Pour les carrés du haut y=6,
ceux du bas y=0. Un moyen très simple de les inverser est donc de mulitplier
y par -1 :
y(nl) = int(nl*-1)%7

script pour graph
Super, notre lundi apparaît bien en haut et notre dimanche en bas.
Et pour rendre un peu plus lisible notre commande plot on peut la séparer sur
plusieurs lignes en les terminant pas des \ :
plot 'nbofcommits.tsv' using (x($0)):(y($0)):1 \
with points \
pointtype 5 pointsize 5 linecolor palette
Étape 10
Si l’on retourne voir le graphique de gitlab on remarque qu’il y a des jours en moins à gauche. En effet, il n’affiche que les 365 derniers jours. Or rappelez vous, notre jeu de donnée contient des jours supplémentaires de l’année précédente pour “remplir” la première semaine. C’est pratique puisque cela nous permet d’avoir recours à l’astuce de l’étape 3. Comment pouvons nous les garder dans le jeu de donnée sans les afficher ? Je propose une solution parmi d’autre qui permet d’introduire l’opérateur ternaire :
plot 'nbofcommits.tsv' u (words(strcol(2))>1 ? x($0):NaN):(y($0)):1 \
with points \
pointtype 5 pointsize 5 linecolor palette
Plusieurs choses ici :
usingest devenuu. Dans gnuplot la plupart des mots clefs peuvent être raccourcis. Cela obfusque un peu les scripts mais c’est bien pratique pour les initié·es. Je me suis retenu jusque là mais la ligne devenant très longue j’ai cédé ici.pointtypepourrait êtrept,withwetc.- Dans une transformation en ligne on utilisait
column(N)ou son raccourci$Npour accéder aux valeurs des colonnes du fichiers ou des pseudo-colonnes. Cette fonction ne renvoie que des valeurs numériques. Si l’on souhaite récupérer une chaîne de caractère il faut utiliser sa soeurstringcolumn(N)ou son raccourcistrcol(N). words()est une fonction prenant en argument une chaîne de caractère et renvoyant son nombre de mots. Les mots sont séparés par des blancs (espaces, tabulations etc).words("abcd")renvoie1,words("a b c d")renvoie4.words(strcol(2))renverra donc le nombre de mots de la seconde colonne.- Les opérateurs
>,?,:.>permet de faire une simple comparaison comme on en trouve dans tous les langages. Ici on vérifie donc si la seconde colonne contient strictement plus qu’un mot. L’opérateur?va vérifier la valeur de vérité de la comparaison qui le précède et opter pour l’expression précédant le:si elle est vraie et celle le suivant si elle est fausse. Ici la valeur de la première colonne sera le résultat dex($0)si la seconde colonne de notre fichier contient au moins deux mots et seraNaNsi elle est contient moins.
Pourquoi est-ce que cela fonctionne ? D’abord parce que cette comparaison permet
effectivement de discriminer entre les “faux” jours en début de fichier, n’ayant
qu’un entier dans leur seconde colonne, et les vrais en ayant quatre. Ensuite
parce que pour gnuplot NaN est particulier. Par défaut, s’il est rencontré
dans l’une des colonnes alors le point ne sera pas tracé.
Si vous testez ce code vous ne verrez pas les carrés disparaître. C’est parce
qu’il nous manque une information essentielle au début de notre script. Si la
fonction words() sépare les mots par des blancs ce n’est pas par hasard,
c’est le comportement par défaut de tout gnuplot. En écrivant strcol(2) on
pense donc faire référence à la colonne avec les dates mais pour gnuplot les
espaces et les tabulations sont tous les deux des séparateurs. La deuxième
colonne contient donc que les entiers de 1 à 7 du début de la colonne des
dates. Pour que gnuplot interprète le fichier comme on le fait, c’est à dire
avec uniquement les tabulations comme séparateur, il faut lui indiquer avant la
commande plot :
set datafile separator "\t"
Et tout fonctionnera comme prévu :

script pour graph
Si jusqu’à maintenant tout s’était bien passé alors que gnuplot n’interprétait pas les données comme on le faisait c’est parce que, par pure coïncidence, tout ce que l’on faisait reposait sur le numéro de ligne ou la première colonne.
Il manque un minimum de contexte à ce graph non ?
Étape 11
On va d’abord faire un peu de place sur le graph pour pouvoir caser du texte :
set tmargin 1
set lmargin 6.5
tmargin pour “top margin”, lmargin pour “left margin”. A gauche on écrit les
jours :
set label "Mon" at -1.5, 0
set label "Thu" at -1.5,-3
set label "Sun" at -1.5,-6
Pour les mois cela est un peu plus compliqué. Puisqu’ils dépendent des données
on ne peut pas les placer “à la main” comme les jours mais on ne veut pas non
plus les afficher pour chaque point. Sinon on aurait 365 chaînes de caractères
qui noirciraient totalement le graph. On va donc à nouveau avoir recours à la
commande plot et l’astuce du NaN :
plot 'nbofcommits.tsv' u (words(strcol(2))>1 ? x($0):NaN):(y($0)):1 \
w p \
pt 5 ps 5 lc palette, \
'' u (x($0)):(word(strcol(2),4) eq "01" ? 1.3:NaN):(word(strcol(2),3)) \
w labels
J’ai tout raccourci comme ça vous pouvez prendre l’habitude de lire des scripts de la sorte sans être perdu·es. Les nouveautés :
Lorsque l’on veut tracer plusieurs choses sur un même graph il faut enchaîner les arguments à la commande
plotsans répéter la commande elle même. Si l’on avait par exemple deux fichiers1.tsvet2.tsvet que l’on voulait les voir ensemble sur le même graphique on pourrait écrire :plot '1.tsv' u ... w ..., '2.tsv' u ... w ...
Dans notre cas les données proviennent du même fichier, on aurait pu repréciser
'nbofcommits.tsv' mais c’est implicite.
- La fonction
word(str,?)qui renvoie le Nième mot de la chaînestr. Ainsiword("a b c d",3)renvoiec. - Le style
with labels. Ce style est similaire àwith pointsmais pour des chaînes de caratères. Il nécessite une troisième colonne non optionnelle qui sera la chaîne affichée. De façon à n’afficher les mois que sur la première semaine on vérifie pour chaque ligne si le dernier mot de la seconde colonne est01. Si oui alors on est le premier d’un nouveau mois et l’ordonnée de la chaîne à afficher est1.3de façon à être légèrement au dessus des carrés. Sinon c’estNaNet la chaîne ne s’affiche pas. La gestion de l’abscisse est équivalente à ce que l’on fait avec les carrés. Finalement on va chercher la chaîne à afficher dans le troisième mot de la seconde colonne.
script pour graph
Et voilà le travail.
Conclusion
Évidemment ce graphique sans interactivité, notamment sans pouvoir cliquer sur les carrés etc n’est pas bien utile. Je pense que cela reste un bon exercice qui permet de voir une quantité surprenante d’astuces gnuplot.
On voulait tracer des carrés et donc w p pt 5 était parfait mais si l’on avait
voulu tracer des rectangles plus arbitraires on aurait pu utiliser le style w
boxxy. D’ailleurs je l’ai initialement fait comme cela avant de voir un
graphique étrangement ressemblant fait avec w p dans le bouquin “gnuplot in
action” que je recommande vivement.
-
ou tout autre logiciel pour faire des graphs ↩
-
c’est à partir de maintenant que le format un peu bizarre de notre tsv commence à nous être utile ↩
-
Aussi le chiffre que l’on cherche est sous nos yeux dans la seconde colonne mais on fait comme si de rien n’était, voir l’addendum. ↩
-
je suis surpris que column renvoie autre chose qu’un entier mais pas moyen de le faire fonctionner sans la conversion. A creuser. ↩
-
qui bouclent, 16 fera référence à la même couleur que 0 ↩